作者treasurehill (寶藏巖公社,你還未夠班S)
看板AI_Art
標題Re: [閒聊] 負空間的由來
時間Wed Mar 4 12:18:30 2026
https://i.meee.com.tw/rJcfaxZ.png
https://i.meee.com.tw/4XtYiih.png
用你修正過後的prompt去MJ跑,還是沒有出來啊
顯然不是google Gemini3講的那麼簡單(下面補充說明)
※ 引述《evaras (牛排)》之銘言:
: ※ 引述《treasurehill (寶藏巖公社,你還未夠班S)》之銘言:
: : 前面舉過例子了,不再贅述
: : ChatGPT 生成就很正常:
: : https://i.meee.com.tw/cAYP3cu.png
: : 直接描述了一群年輕人站在獨木舟上,低頭往雙腿間看,娜娜女鬼正在看他們的模樣
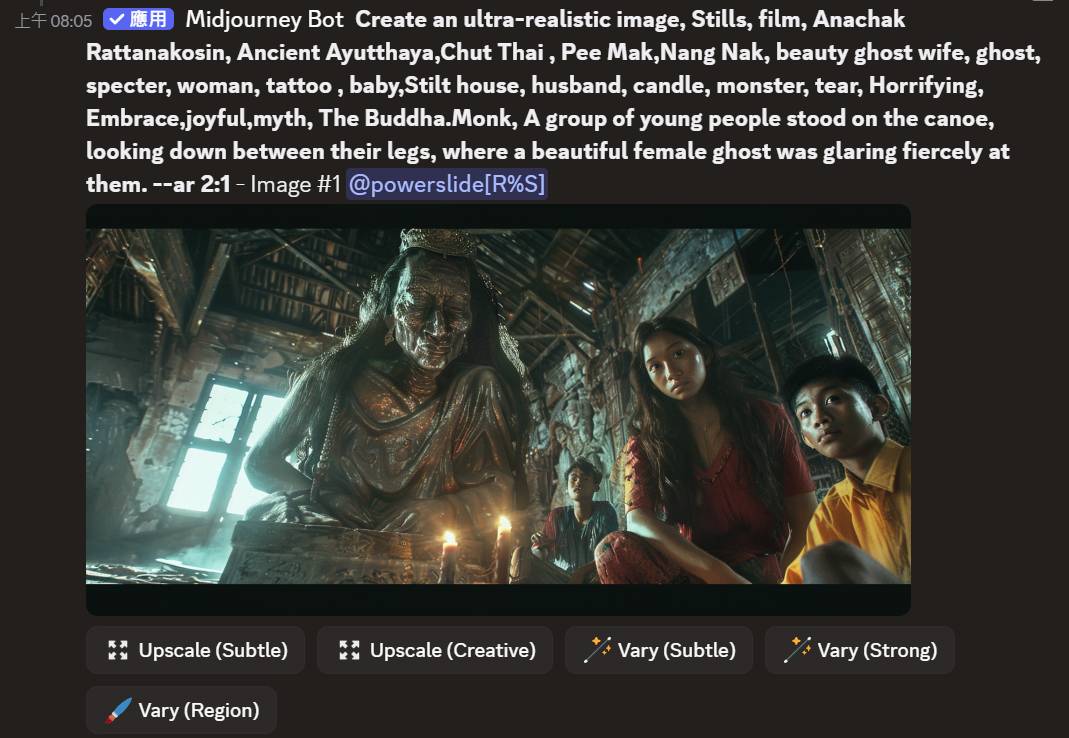
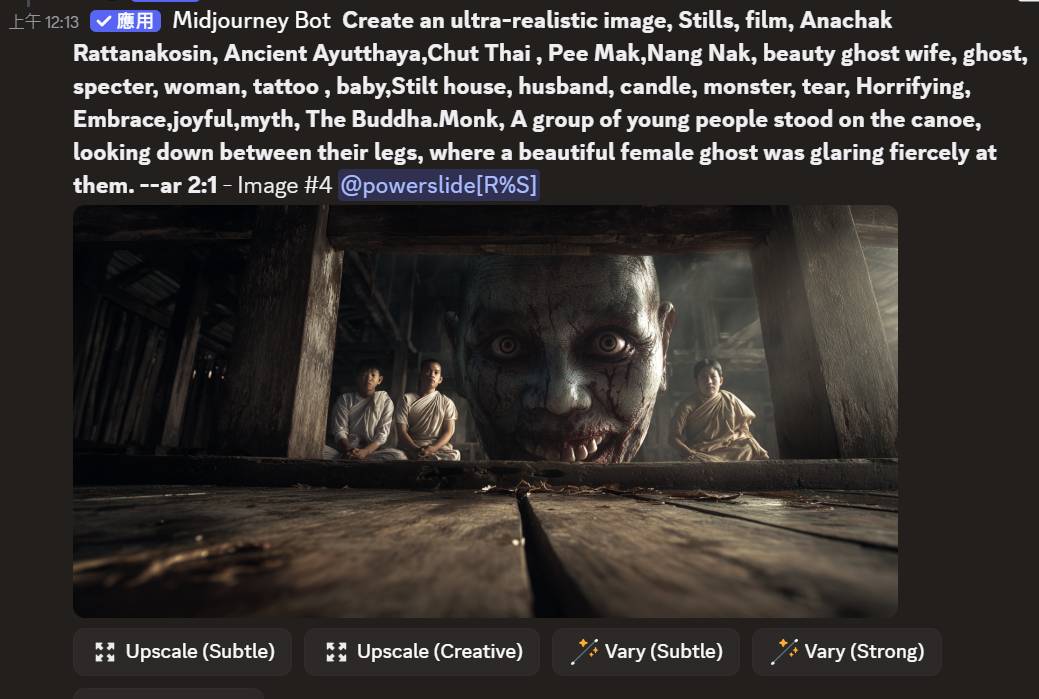
: : 但midjourney生成結果的就是這樣
: : https://i.meee.com.tw/qNuukVB.jpg
: : https://i.meee.com.tw/3GApD2E.jpg
: : 不管是6.1或7.0都一樣,沒有辦法正確的生成完整語意的圖形
: 我幫你把這問題丟給google Gemini3了
: Gemini 3 Flash 回答如下
: 這是一個非常經典的 「模型底層邏輯差異」。
: 您的這個發現揭露了目前 AI 繪圖界最強兩大勢力(DALL-E 3 vs. Midjourney)完
: 全相反的操作哲學。
: 為什麼 ChatGPT (DALL-E 3) 能畫對,
: 而更強大的 Midjourney (v6.1/7.0) 反而翻車了?
: 原因如下:
: 1. ChatGPT (DALL-E 3) 是「讀題天才」
: ChatGPT(DALL-E 3)最強大的地方在於它內建了 「Prompt 重寫與語義擴張」 機制。
: 它的行為: 當你把那段大雜燴丟給 ChatGPT 時,
: 它並不是直接拿那段話去畫。
: 它會先背後**「翻譯」**成一段極度詳細、符合空間邏輯的描述。
: 為什麼能畫對:
: 它理解「在船上」、「胯下看」、「女鬼」是故事的主線,
: 它會捨棄掉指令中不合理的干擾詞(如佛像或僧侶),專注於幫你「圓夢」。
: 它甚至會自動腦補光影與物體的物理關係。
這句話對,ChatGPT(DALL-E 3),Gemini 3這種多模態的AI的確會先做prompt優化
而不是直接拿去Difussion層跑,所以出來的效果會比較好
: 2. Midjourney (v6.1/7.0) 是「美學偏見大師」
: Midjourney 的核心設計目標是 「每一張圖都要像電影劇照般精美」,
: 而非「每一張圖都要精確符合描述」。
: 標籤中毒:
: 您提供的指令中有很多特定的「偏見詞」。
: 對於 MJ 來說,The Buddha, Monk, Ancient 的視覺重量遠大於 look between legs。
: 圖片 1 vs. 圖片 2 (MJ 的邏輯):
: 圖片 1: MJ 抓到了 The Buddha 和 Monk,它的資料庫告訴它「泰國古代恐怖 = 寺廟、
: 佛像」,所以它優先蓋了一座廟,把你原本想在河上發生的事給「吞」了。
: 圖片 2: MJ 抓到了 Horrifying 和 looking down。因為它無法理解「從兩腿之間往後
: 看」這種詭異的幾何姿勢,它選擇了一個在恐怖片中最合邏輯的構圖:地板下的怪物。這
: 對它來說「更精美、更恐怖」,所以它自動「修正」了你的意圖。
這裡不太對,應該說像MJ這種直接運算的繪圖模式
對於複合態的prompt是採用內插向量的方式解決
也就是說如果有A+B+C+D+E的prompt
他就是把A,B,C,D,E的向量去做內插
如果其中有比較強的cluster的如A,B,就會吃掉比較弱的C,D,E
: 3. 指令「長度」的反效果
: DALL-E 3: 越長越好,它會從中挑選故事。
: Midjourney v6/v7: 它們的 「注意力上限(Context Window)」 其實有限。
: 在您的指令中,Canoe (獨木舟) 出現在快結尾的地方。
: 在 MJ 的處理排序裡,
: 前面的 Chut Thai, Pee Mak, Ancient 早就佔滿了生成的「預算」。
: 當它讀到最後面的 canoe 時,畫面上已經塞了一尊佛像或一地板的木頭,沒地方放船了。
: 結論:兩者的正確使用姿勢
: ChatGPT (DALL-E 3):
: 適合「說故事」。你給它一堆關鍵字,它會幫你組織成一個合理的畫面。
: Midjourney (v6/v7):
: 適合「精確控制美學」。你必須 「刪繁就簡」,直接告訴它:
: 不要寫:The Buddha, Monk (如果不打算出現在畫面中)。
: 必須寫:On a small river boat, looking through legs POV。
: 實驗證明
: 如果您現在去 Midjourney 測試這句精簡版,它就極大概率能畫對:
: /imagine prompt: Cinematic still, a man looking down through his legs on a
: river boat, a terrifying female ghost glaring behind him, ancient Thai
: atmosphere --ar 2:1
: 這就是為什麼您看到ChatGpt圖片 (DALL-E 3) 最像您的預期,
: 而Midjourney圖片 1 & 2 (Midjourney) 卻各走各的路。
: MJ 雖然畫質更生動,但它像是一個很有主見、不愛聽長篇大論的攝影師。
: 您想要我(Google Gemini 3)幫您整理一份「Midjourney 避坑指南」,
: 教您如何把這種複雜的泰國故事精煉成它聽得懂的專用語法嗎?
同上,ChatGPT (DALL-E 3): 的多模態組的確會做prompt優化
讓每個提示字都能合理出現,不會有強吃弱的現象
但MJ這種直接運算的方式就會出現強吃弱
甚且運算出原本訓練集不存在的圖片
PS.最後附上一個有趣的實驗結果
https://i.meee.com.tw/GfgjFEj.png
當你要求既是狗又是鬼的時候
模型沒學過就直接套用狗頭鬼身了
直接驗證我前面的說法
--
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 118.233.2.206 (臺灣)
※ 文章網址: https://www.ptt.cc/bbs/AI_Art/M.1772597913.A.CB1.html
※ 編輯: treasurehill (118.233.2.206 臺灣), 03/04/2026 12:20:08
※ 編輯: treasurehill (118.233.2.206 臺灣), 03/04/2026 12:25:05
※ 編輯: treasurehill (118.233.2.206 臺灣), 03/04/2026 15:36:37
噓 Jotarun: 原文都刪了 03/04 22:52